This document (notebook) describes three ways of making mazes (or labyrinths) using graphs. The first two are based on rectangular grids; the third on a hexagonal grid.
All computational graph features discussed here are provided by the Graph functionalities of Wolfram Language.
TL;DR
Just see the maze pictures below. (And try to solve the mazes.)
Procedure outline
The first maze is made by a simple procedure which is actually some sort of cheating:
A regular rectangular grid graph is generated with random weights associated with its edges.
The (minimum) spanning tree for that graph is found.
That tree is plotted with exaggeratedly large vertices and edges, so the graph plot looks like a maze.
This is “the cheat” — the maze walls are not given by the graph.
The second maze is made “properly”:
Two interlacing regular rectangular grid graphs are created.
The second one has one less row and one less column than the first.
The vertex coordinates of the second graph are at the centers of the rectangles of the first graph.
The first graph provides the maze walls; the second graph is used to make paths through the maze.
In other words, to create a solvable maze.
Again, random weights are assigned to edges of the second graph, and a minimum spanning tree is found.
There is a convenient formula that allows using the spanning tree edges to remove edges from the first graph.
In that way, a proper maze is derived.
The third maze is again made “properly” using the procedure above with two modifications:
Two interlacing regular grid graphs are created: one over a hexagonal grid, the other over a triangular grid.
The hexagonal grid graph provides the maze walls; the triangular grid graph provides the maze paths.
Since the formula for wall removal is hard to derive, a more robust and universal method based on nearest neighbors is used.
Simple Maze
In this section, we create a simple, “cheating” maze.
Remark: The steps are easy to follow, given the procedure outlined in the introduction.
The “maze” above looks like a maze because the vertices and edges are rectangular with matching sizes, and they are thicker than the spaces between them. In other words, we are cheating.
To make that cheating construction clearer, let us plot the shortest path from the bottom left to the top right and color the edges in pink (salmon) and the vertices in red:
finder = Nearest[Thread[GraphEmbedding[g1] -> VertexList[g1]]]
Take a maze edge and its vertex points:
e = First@EdgeList[mazePath];
aMazePathCoords = Association@Thread[VertexList[mazePath] -> GraphEmbedding[mazePath]];
points = List @@ (e /. aMazePathCoords)
Find the edge’s midpoint and the nearest wall-graph vertices:
This document (notebook) discusses number theory properties and relationships of the integer 2026.
The integer 2026 is semiprime and a happy number, with 365 as one of its primitive roots. Although 2026 may not be particularly noteworthy in number theory, this provides a great excuse to create various elaborate visualizations that reveal some interesting aspects of the number.
A happy number is a number for which iteratively summing the squares of its digits eventually reaches 1 (e.g., 13 -> 10 -> 1). Here is a check that 2026 is happy:
ResourceFunction["HappyNumberQ"][2026]
Out[]= True
Here is the corresponding trail of digit-square sums:
The decomposition of $2026$ as $2 * 1013$ means the multiplicative group modulo $2026$ has primitive roots. A primitive root exists for an integer $n$ if and only if $n$ is $1$, $2$,$4$, $p^k$ , or $2 p^k$ , where $k$ is an odd prime and $k>0$ .
We can check additional facts about 2026, such as whether it is “square-free” , among other properties. However, let us compare these with the feature-rich 2025 in the next section.
Comparison with 2025
Here is a side-by-side comparison of key number theory properties for 2025 and 2026.
Property
2025
2026
Notes
Prime or Composite
Composite
Composite
Both non-prime.
Prime Factorization
3^4 * 5^2 (81 * 25)
2 * 1013
2025 has repeated small primes; 2026 is a semiprime (product of two distinct primes).
Number of Divisors
15 (highly composite for its size)
4 (1, 2, 1013, 2026)
2025 has many divisors; 2026 has very few.
Perfect Square
Yes (45^2 = 2025)
No
Major highlight for 2025—rare square year.
Sum of Cubes
Yes (1^3 + 2^3 + … + 9^3 = (1 + … + 9)^2 = 2025)
No
Iconic property for 2025 (Nicomachus’s theorem).
Happy Number
No (process leads to cycle including 4)
Yes (repeated squared digit sums reach 1)
Key point for 2026—its main “happy” trait.
Harshad Number
Yes (divisible by 9)
No (not divisible by 10)
2025 qualifies; 2026 does not.
Primitive Roots
No
Yes
This is a relatively rare property to have.
Other Notable Traits
{(20 + 25)^2 = 2025, Sum of first 45 odd numbers, Deficient number, Many pattern-based representations}
{Even number, Deficient number, Few special patterns}
2025 is packed with elegant properties; 2026 is more “plain” beyond being happy.
Overall “Interest” Level
Highly interesting—celebrated in math communities for squares, cubes, and patterns
Relatively uninteresting—basic semiprime with no standout geometric or sum properties
Reinforces blog’s angle.
To summarize:
2025 stands out as a mathematically rich number, often highlighted in puzzles and articles for its perfect square status and connections to sums of cubes and odd numbers.
2026 , in contrast, has fewer flashy properties — it’s a straightforward even semiprime — but it qualifies as a happy number and it has a primitive root.
Here is a computationally generated comparison table of most of the properties found in the table above:
Let us create and plot a graph showing the trails of all happy numbers less than or equal to 2026. Below, we identify these numbers and their corresponding trails:
There is a theorem by Gauss stating that any integer can be represented as a sum of at most three triangular numbers. Here we find an “interesting” solution:
sol = FindInstance[{2026 == PolygonalNumber[i] + PolygonalNumber[j] + PolygonalNumber[k], i > 10, j > 10, k > 10}, {i, j, k}, Integers]
Remark: It is interesting that 365 (the number of days in a common calendar year) is a primitive root of the multiplicative group generated by 2026 . Not many years have this property this century; many do not have primitive roots at all.
Here we find the position of 2026 in that sequence:
Position[seq, 2026]
Out[]= {{18}}
Given the title of the sequence and the extracted position of $2026$ , this means that the number of disconnected 4-regular graphs with 17 vertices is $2026$. ($17$ because the sequence offset is $0$.) Let us create a few graphs from that set by using the 5-vertex complete graph $\left(K_5\right.$) and circulant graphs . Here is an example of such a graph:
Number theory provides many opportunities for visualizations, so I included utilities for some of the popular patterns in “Math::NumberTheory”, [AAp1] and “NumberTheoryUtilities”.
The number of years in this century that have primitive roots and have 365 as a primitive root is less than the number of years that are happy numbers.
I would say I spent too much time finding a good, suitable, Christmas-themed combination of colors for the trails graph.
This document (notebook) discusses different combinations of Grammar-Based Parser-Interpreters (GBPI) and Large Language Models (LLMs) to generate executable code from Natural Language Computational Specifications (NLCM). We have the soft assumption that the NLCS adhere to a certain relatively small Domain Specific Language (DSL) or use terminology from that DSL. Another assumption is that the target software packages are not necessarily well-known by the LLMs, i.e. direct LLM requests for code using them would produce meaningless results.
We want to do such combinations because:
GBPI are fast, precise, but with a narrow DSL scope
LLMs can be unreliable and slow, but with a wide DSL scope
Because of GBPI and LLMs are complementary technologies with similar and overlapping goals the possible combinations are many. We concentrate on two of the most straightforward designs: (1) judged parallel race of methods execution, and (2) using LLMs as a fallback method if grammar parsing fails. We show asynchronous programmingimplementations for both designs using the Wolfram Language function LLMGraph.
The rest of the document is structured as follows:
Initial grammar-LLM combinations
Assumptions, straightforward designs, and trade-offs
Comprehensive combinations enumeration (attempt)
Tabular and morphological analysis breakdown
Three methods for parsing ML DSL specs into Raku code
One grammar-based, two LLM-based
Parallel execution with an LLM judge
Straightforward, but computationally wasteful and expensive
Grammar-to-LLM fallback mechanism
The easiest and most robust solution
Concluding comments and observations
TL;DR
Combining grammars and LLMs produces robust translators.
Three translators with different faithfulness and coverage are demonstrated and used.
Two of the simplest, yet effective, combinations are implemented and demonstrated.
Parallel race and grammar-to-LLM fallback.
Asynchronous implementations with LLM-graphs are a very good fit!
Just look at the LLM-graph plots (and be done reading.)
Initial Combinations and Associated Assumptions
The goal is to combine grammar-based parser-interpreters with LLMs in order to achieve robust parsing and interpretation of computational workflow specifications.
Here are some example combinations of these approaches:
A few methods, both grammar-based and LLM-based, are initiated in parallel. Whichever method produces a correct result first is selected as the answer.
This approach assumes that when the grammar-based methods are effective, they will finish more quickly than the LLM-based methods.
The grammar method is invoked first; if it fails, an LLM method (or a sequence of LLM methods) is employed.
LLMs are utilized at the grammar-rule level to provide matching objects that the grammar can work with.
If the grammar method fails, an LLM normalizer for user commands is invoked to generate specifications that the grammar can parse.
It is important to distinguish between declarative specifications and those that prescribe specific steps.
For a workflow given as a list of steps the grammar parser may successfully parse most steps, but LLMs may be required for a few exceptions.
The main trade-off in these approaches is as follows:
Grammar methods are challenging to develop but can be very fast and precise.
Precision can be guaranteed and rigorously tested.
LLM methods are quicker to develop but tend to be slower and can be unreliable, particularly for less popular workflows, programming languages, and packages.
Also, combinations based on LLM tools (aka LLM external function calling) are not considered because LLM-tools invocation is too unpredictable and unreliable.
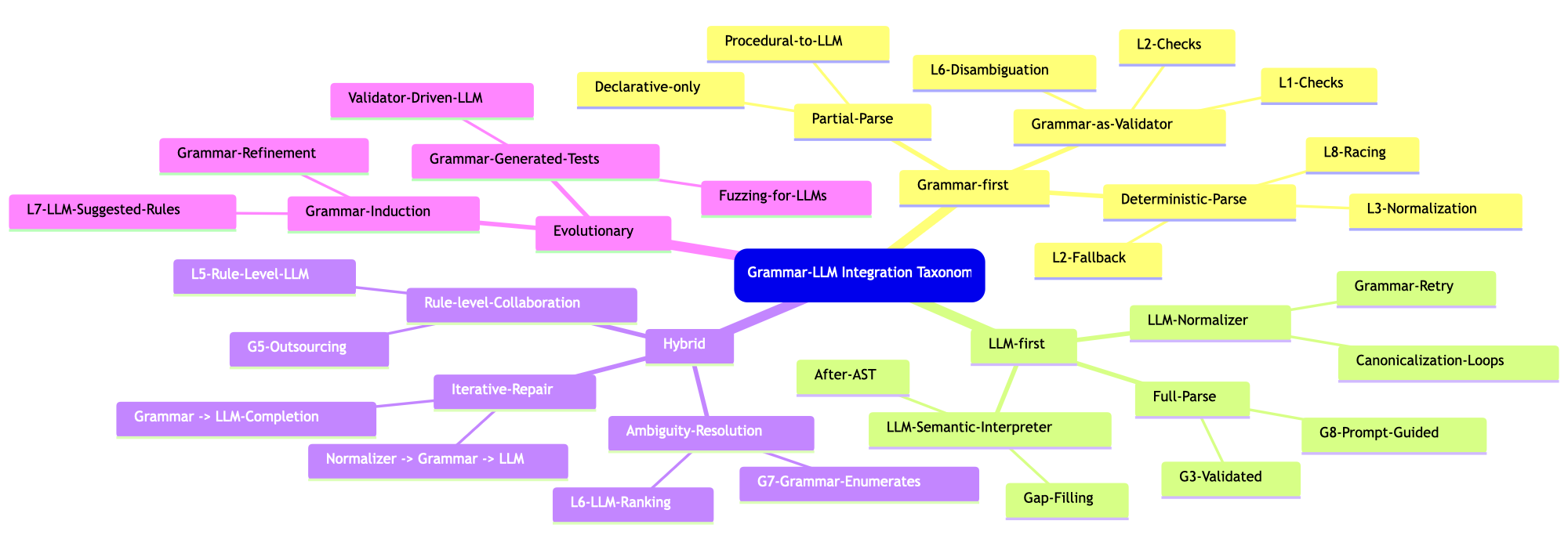
Comprehensive breakdown (attempt)
This section has a “concise” table that expands the combinations list above into the main combinatorial strategies for Grammar *** LLMs** for robust parsing and interpretation of workflow specifications. The table is not an exhaustive list of such combinations, but illustrates their diversity and, hopefully, can give ideas for future developments.
A few summary points (for table’s content/subject):
The most robust systems combine grammar precision with LLM adaptability , typically by putting grammars first and using LLMs for repair, normalization, expansions, or semantic interpretation (i.e. “fallback”.)
Table: Combination Patterns for Parsing Workflow Specifications
tbl = Dataset[{<|"ID" -> 1, "CombinationPattern" -> "Parallel Race: Grammar + LLM", "Description" -> "Launch grammar-based parsing and one or more LLM interpreters in parallel; whichever yields a valid parse first is accepted.", "Pros" -> {"Fast when grammar succeeds", "Robust fallback", "Reduces latency unpredictability of LLMs"}, "ConsTradeoffs" -> {"Requires orchestration", "Need a validator for LLM output"}|>, <|"ID" -> 2, "CombinationPattern" -> "Grammar-First, LLM-Fallback", "Description" -> "Try grammar parser first; if it fails, invoke LLM-based parsing or normalization.", "Pros" -> {"Deterministic preference for grammar", "Testable correctness when grammar succeeds"}, "ConsTradeoffs" -> {"LLM fallback may produce inconsistent structures"}|>, <|"ID" -> 3, "CombinationPattern" -> "LLM-Assisted Grammar (Rule-Level)", "Description" -> "Individual grammar rules delegate to an LLM for ambiguous or context-heavy matching; LLM supplies tokens or AST fragments.", "Pros" -> {"Handles complexity without inflating grammar", "Modular LLM usage"}, "ConsTradeoffs" -> {"LLM behavior may break rule determinism", "Harder to reproduce"}|>, <|"ID" -> 4, "CombinationPattern" -> "LLM Normalizer -> Grammar Parser", "Description" -> "When grammar fails, LLM rewrites/normalizes input into a canonical form; grammar is applied again.", "Pros" -> {"Grammar remains simple", "Leverages LLM skill at paraphrasing"}, "ConsTradeoffs" -> {"Quality depends on normalizer", "Feedback loops possible"}|>, <|"ID" -> 5, "CombinationPattern" -> "Hybrid Declarative vs Procedural Parsing", "Description" -> "Grammar extracts structural/declarative parts; LLM interprets procedural/stepwise parts or vice versa.", "Pros" -> {"Each subsystem tackles what it's best at", "Reduces grammar complexity"}, "ConsTradeoffs" -> {"Harder to maintain global consistency", "Requires AST stitching logic"}|>, <|"ID" -> 6, "CombinationPattern" -> "Grammar-Generated Tests for LLM", "Description" -> "Grammar used to generate examples and counterexamples; LLM outputs are validated against grammar constraints.", "Pros" -> {"Powerful for verifying LLM outputs", "Reduces hallucinations"}, "ConsTradeoffs" -> {"Grammar must encode constraints richly", "Validation pipeline required"}|>, <|"ID" -> 7, "CombinationPattern" -> "LLM as Adaptive Heuristic for Grammar Ambiguities", "Description" -> "When grammar yields multiple parses, LLM chooses or ranks the \"most plausible\" AST.", "Pros" -> {"Improves disambiguation", "Good for underspecified workflows"}, "ConsTradeoffs" -> {"LLM can pick syntactically impossible interpretations"}|>, <|"ID" -> 8, "CombinationPattern" -> "LLM as Semantic Phase After Grammar", "Description" -> "Grammar creates an AST; LLM interprets semantics, fills in missing steps, or resolves vague ops.", "Pros" -> {"Clean separation of syntax vs semantics", "Grammar ensures correctness"}, "ConsTradeoffs" -> {"Semantic interpretation may drift from syntax"}|>, <|"ID" -> 9, "CombinationPattern" -> "Self-Healing Parse Loop", "Description" -> "Grammar fails -> LLM proposes corrections -> grammar retries -> if still failing, LLM creates full AST.","Pros" -> {"Iterative and robust", "Captures user intent progressively"}, "ConsTradeoffs" -> {"More expensive; risk of oscillation"}|>, <|"ID" -> 10, "CombinationPattern" -> "Grammar Embedding Inside Prompt Templates", "Description" -> "Grammar definitions serialized into the prompt, guiding the LLM to conform to the grammar (soft constraints).", "Pros" -> {"Faster than grammar execution in some cases", "Encourages consistent structure"}, "ConsTradeoffs" -> {"Weak guarantees", "LLM may ignore grammar"}|>, <|"ID" -> 11, "CombinationPattern" -> "LLM-Driven Grammar Induction or Refinement", "Description" -> "LLM suggests new grammar rules or transformations; developer approves; the grammar evolves over time.", "Pros" -> {"Faster grammar evolution", "Useful for new workflow languages"}, "ConsTradeoffs" -> {"Requires human QA", "Risk of regressing accuracy"}|>, <|"ID" -> 12, "CombinationPattern" -> "Regex Engine as LLM Guardrail", "Description" -> "Regex or token rules used to validate or filter LLM results before accepting them.", "Pros" -> {"Lightweight constraints", "Useful for quick prototyping"}, "ConsTradeoffs" -> {"Regex too weak for complex syntax"}|>}];
tbl = tbl[All, KeyDrop[#, "ID"] &];
tbl = tbl[All, ReplacePart[#, "Pros" -> ColumnForm[#Pros]] &];
tbl = tbl[All, ReplacePart[#, "ConsTradeoffs" -> ColumnForm[#ConsTradeoffs]] &];
tbl = tbl[All, Style[#, FontFamily -> "Times New Roman"] & /@ # &];
ResourceFunction["GridTableForm"][tbl]
#
CombinationPattern
Description
Pros
ConsTradeoffs
1
Parallel Race: Grammar + LLM
Launch grammar-based parsing and one or more LLM interpreters in parallel; whichever yields a valid parse first is accepted.
{{Fast when grammar succeeds}, {Robust fallback}, {Reduces latency unpredictability of LLMs}}
{{Requires orchestration}, {Need a validator for LLM output}}
2
Grammar-First, LLM-Fallback
Try grammar parser first; if it fails, invoke LLM-based parsing or normalization.
{{Deterministic preference for grammar}, {Testable correctness when grammar succeeds}}
{{LLM fallback may produce inconsistent structures}}
3
LLM-Assisted Grammar (Rule-Level)
Individual grammar rules delegate to an LLM for ambiguous or context-heavy matching; LLM supplies tokens or AST fragments.
{{Handles complexity without inflating grammar}, {Modular LLM usage}}
{{LLM behavior may break rule determinism}, {Harder to reproduce}}
4
LLM Normalizer -> Grammar Parser
When grammar fails, LLM rewrites/normalizes input into a canonical form; grammar is applied again.
{{Grammar remains simple}, {Leverages LLM skill at paraphrasing}}
{{Quality depends on normalizer}, {Feedback loops possible}}
5
Hybrid Declarative vs Procedural Parsing
Grammar extracts structural/declarative parts; LLM interprets procedural/stepwise parts or vice versa.
{{Each subsystem tackles what it’s best at}, {Reduces grammar complexity}}
{{Harder to maintain global consistency}, {Requires AST stitching logic}}
6
Grammar-Generated Tests for LLM
Grammar used to generate examples and counterexamples; LLM outputs are validated against grammar constraints.
{{Powerful for verifying LLM outputs}, {Reduces hallucinations}}
{{Grammar must encode constraints richly}, {Validation pipeline required}}
7
LLM as Adaptive Heuristic for Grammar Ambiguities
When grammar yields multiple parses, LLM chooses or ranks the “most plausible” AST.
{{Improves disambiguation}, {Good for underspecified workflows}}
{{LLM can pick syntactically impossible interpretations}}
8
LLM as Semantic Phase After Grammar
Grammar creates an AST; LLM interprets semantics, fills in missing steps, or resolves vague ops.
{{Clean separation of syntax vs semantics}, {Grammar ensures correctness}}
{{Semantic interpretation may drift from syntax}}
9
Self-Healing Parse Loop
Grammar fails -> LLM proposes corrections -> grammar retries -> if still failing, LLM creates full AST.
{{Iterative and robust}, {Captures user intent progressively}}
{{More expensive; risk of oscillation}}
10
Grammar Embedding Inside Prompt Templates
Grammar definitions serialized into the prompt, guiding the LLM to conform to the grammar (soft constraints).
{{Faster than grammar execution in some cases}, {Encourages consistent structure}}
{{Weak guarantees}, {LLM may ignore grammar}}
11
LLM-Driven Grammar Induction or Refinement
LLM suggests new grammar rules or transformations; developer approves; the grammar evolves over time.
{{Faster grammar evolution}, {Useful for new workflow languages}}
{{Requires human QA}, {Risk of regressing accuracy}}
12
Regex Engine as LLM Guardrail
Regex or token rules used to validate or filter LLM results before accepting them.
{{Lightweight constraints}, {Useful for quick prototyping}}
{{Regex too weak for complex syntax}}
Diversity reasons
The diversity of combinations in the table above arises because Raku grammars and LLMs occupy fundamentally different but highly complementary positions in the parsing spectrum.
Raku grammars provide determinism, speed, verifiability, and structural guarantees, but they require upfront design and struggle with ambiguity, informal input, and evolving specifications.
LLMs, in contrast, excel at normalization, semantic interpretation, ambiguity resolution, and adapting to fluid or poorly defined languages, yet they lack determinism, may hallucinate, and are slower.
When these two technologies meet, every architectural choice — who handles syntax, who handles semantics, who runs first, who validates whom, who repairs or refines — defines a distinct strategy.
Hence, the design space naturally expands into many valid hybrid patterns rather than a single “best” pipeline.
That said, the fallback pattern implemented below can be considered the “best option” from certain development perspectives because it is simple, effective, and has fast execution times.
This section demonstrates the use of three different translation methods:
Grammar-based parser-interpreter of computational workflows
LLM-based translator using few-shot learning with relevant DSL examples
Natural Language Processing (NLP) interpreter using code templates and LLMs to fill-in the corresponding parameters
The translators are ordered according of their faithfulness, most faithful first. It can be said that at the same time, the translators are ordered according to their coverage — widest coverage is by the last.
Grammar-based
Here a recommender pipeline specified with natural language commands is translated into Raku code of the package “ML::SparseMatrixRecommender” using a sub of the paclet “DSLTranslation”:
spec = "create from dsData; apply LSI functions IDF, None, Cosine; recommend by profile for passengerSex:male, and passengerClass:1st; join across using dsData; echo the pipeline value";
The function DSLTranslation uses a web service by default but if Raku and the package “DSL::Translators” are installed it can use the provided Command Line Interface (CLI):
LLM translations can be done using a set of from-to rules. This is the so-called few shot learning of LLMs. The paclet “DSLExamples” has a collection of such examples for different computational workflows. (Mostly ML at this point.) The examples are hierarchically organized by programming language and workflow name; see the resource file “dsl-examples.json”, or execute DSLExamples[].
Here is a table that shows the known DSL translation examples in “DSL::Examples” :
Here is a recommender pipeline specified with natural language commands:
spec = "new recommender; create from @dsData; apply LSI functions IDF, None, Cosine; recommend by profile for passengerSex:male, and passengerClass:1st; join across with @dsData on \"id\"; echo the pipeline value; classify by profile passengerSex:female, and passengerClass:1st on the tag passengerSurvival; echo value";
commands = StringSplit[spec, ""];
Translate to WL code line-by-line:
res = LLMPipelineSegment[] /@ commands; res = Map[StringTrim@StringReplace[#, RegularExpression["Output\h*:"] -> ""] &, res];
res = StringRiffle[res, "==>"]
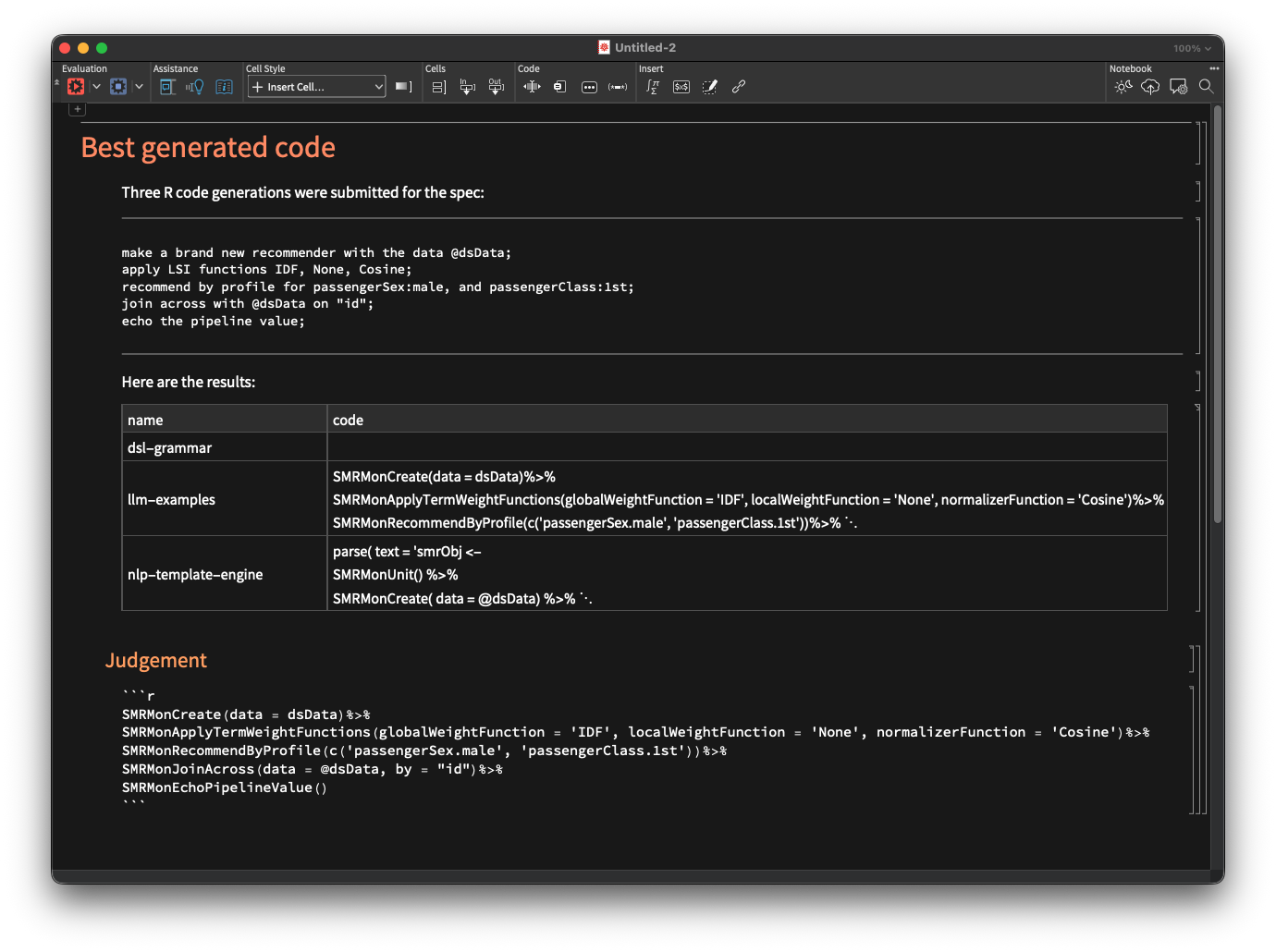
tmplJudge = StringTemplate["Choose the generated code that most fully adheres to the spec:\\n\\n\\n`spec`\\n\\n\\nfrom the following `lang` generation results:\\n\\n\\n1) DSL-grammar:\\n`dslGrammar`\\n\\n\\n2) LLM-examples:\\n`llmExamples`\\n\\n\\n3) NLP-template-engine:\\n`nlpTemplateEngine`\\n\\n\\nand copy it:"]
spec = " make a brand new recommender with the data @dsData; apply LSI functions IDF, None, Cosine; recommend by profile for passengerSex:male, and passengerClass:1st; join across with @dsData on \"id\"; echo the pipeline value; ";
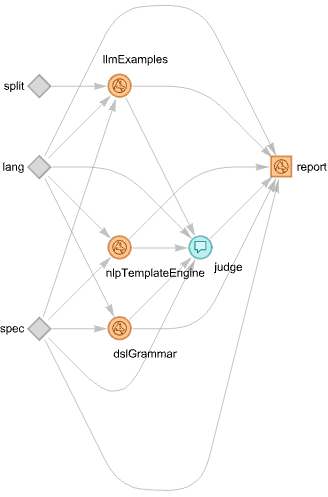
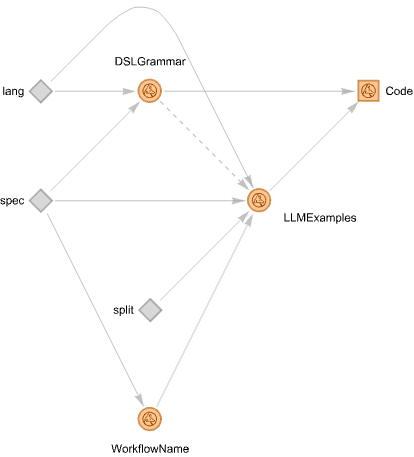
Instead of having DSL-grammar- and LLM computations running in parallel, we can make an LLM-graph in which the LLM computations are invoked if the DSL-grammar parsing-and-interpretation fails. In this section we make such a graph.
Before making the graph let us also generalize it to work with other ML workflows, not just recommendations.
Let us make an LLM function with a similar functionality. I.e. an LLM-function that classifies a natural language computation specification into workflow labels used by “DSLExamples”. Here is such a function using the sub LLMClassify provided by “NLPTemplateEngine”:
Here the LLM graph is run over a spec that can be parsed by DSL-grammar (notice the very short computation time):
Here is the obtained result:
Here is a spec that cannot be parsed by the DSL-grammar interpreter — note that there is just a small language change in the first line:
spec = " create from @dsData; apply LSI functions IDF, None, Cosine; recommend by profile for passengerSex:male, and passengerClass:1st; join across with @dsData on \"id\"; echo the pipeline value; ";
Nevertheless, we obtain a correct result via LLM-examples:
Let us specify another workflow — for ML-classification with Wolfram Language — and run the graph:
spec = " use the dataset @dsData; split the data into training and testing parts with 0.8 ratio; make a nearest neighbors classifier; show classifier accuracy, precision, and recall; echo the pipeline value; ";
Using LLM graphs gives the ability to impose desired orchestration and collaboration between deterministic programs and LLMs.
By contrast, the “inversion of control” of LLM – tools is “capricious.”
LLM-graphs are both a generalization of LLM-tools, and a lower level infrastructural functionality than LLM-tools.
The LLM-graph for the parallel-race translation is very similar to the LLM-graph for comprehensive document summarization described in [AA4].
The expectation that DSL examples would provide both fast and faithful results is mostly confirmed in ≈20 experiments.
Using the NLP template engine is also fast because LLMs are harnessed through QAS.
The DSL examples translation had to be completed with a workflow classifier.
Such classifiers are also part of the implementations of the other two approaches .
The grammar – based one uses a deterministic classifier, [AA1]
The NLP template engine uses an LLM classifier .
An interesting extension of the current work is to have a grammar-LLM combination in which when the grammar fails then the LLM “normalizes” the specs until the grammar can parse them.
Currently, LLMGraph does not support graphs with cycles, hence this approach “can wait” (or be implemented by other means .)
Multiple DSL examples can be efficiently derived by random sentence generation with different grammars.
Similar to the DSL commands classifier making approach taken in [AA1] .
LLMs can be also used to improve and extend the DSL grammars.
And it is interesting to consider automating that process, instead of doing it via human supervision.






























{kind=link}