This blog post shows examples of quantile regression robustness. The quantile regression curves (called “regression quantiles”) are computed with the Mathematica package QuantileRegression.m hosted at the MathematicaForPrediction project at GitHub. Quantile regression was introduced by Koenker and Bassett in 1978; detailed theoretical descriptions and discussions are given in the book “Quantile regression” by Koenker.
This blog post extends the previous blog post.
Here is a scattered points graph based on a simple deterministic model with a simple heteroscedasticity (the variance varies with x):
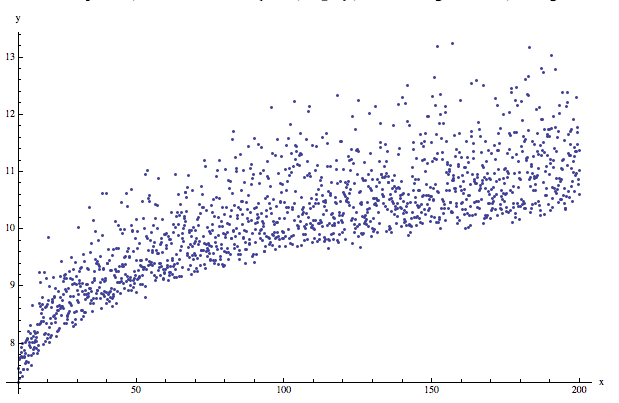
The data was generated with the Mathematica command:
{#, 5 + Log[#] + RandomReal[SkewNormalDistribution[0, Log[#]/5, 12]]} & /@ Range[10,200,0.126751]
Looking at the plot we would assume that the model for the data is
Y = β0 +β1 * X + β3 * log(X).
Here is a plot of the data and the regression quantiles:

Let us demonstrate the robustness of the regression quantiles with the data of the previous example. Suppose that for some reason 50% of the data y-values greater than 11.25 are altered by multiplying them with a some greater than 1 factor, say, α = 1.8 . Then the altered data looks like this:

Here is a plot of altered data and the regression quantiles and least squares fit for the altered data:

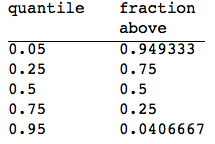
Let us pair up the old regression quantile formulas with the new ones. We can see that the new regression quantiles computed for 0.05, 0.25, and 0.5 have not changed significantly:

Also, there is a significant change in least squares fit:
(i) original data: 5.02011 + 0.000708203 x + 1.14048 Log[x],
(ii) altered dataL 6.60508 + 0.0183379 x + 0.494545 Log[x].
Here is a table of applying the altered regression quantiles to the original data:

Now let us do a different type of alternation of the original data. Suppose that for some reason 70 % of the data Y-values above 0.95 regression quantile are the altered by multiplying them with a some greater than 1 factor, say, α = 10 . Then the altered data looks like this (using a log-plot):

Here is a plot of the altered data and all fitted functions:

Note that the least squares fit is quite off (the plot has a logarithmic scale on the y-axis). We can see that the new regression quantiles computed for 0.05, 0.25, 0.5, 0.75, and 0.95 have not changed significantly:

Here is a table of applying the altered regression quantiles to the original data:
The examples clearly demonstrate the robustness of quantile regression when compared to the least squares fit. As in the single distribution case, computing quantiles can be very useful for identifying outliers. For example, we can do the regression analogue of standardizing the data by subtracting the median and dividing by the interquartile distances, and declare any point outside of a specified range as an outlier.










